
The F-test for equal variances helps you check if two populations have similar variability by comparing their sample variances. You start by calculating the ratio of the larger to the smaller variance, then compare this value to a critical number from the F-distribution table based on your sample sizes and significance level. If the ratio exceeds the critical value, you conclude the variances are unequal. Keep exploring to understand how to interpret and apply this test effectively.
Key Takeaways
- The F-test compares variances of two samples to assess if they are statistically similar.
- It calculates the ratio of sample variances and compares it to a critical F-distribution value.
- Assumes data are normally distributed and free of outliers for accurate results.
- A ratio close to 1 suggests equal variances; significant deviations indicate differences.
- Proper interpretation depends on sample size, significance level, and adherence to test assumptions.
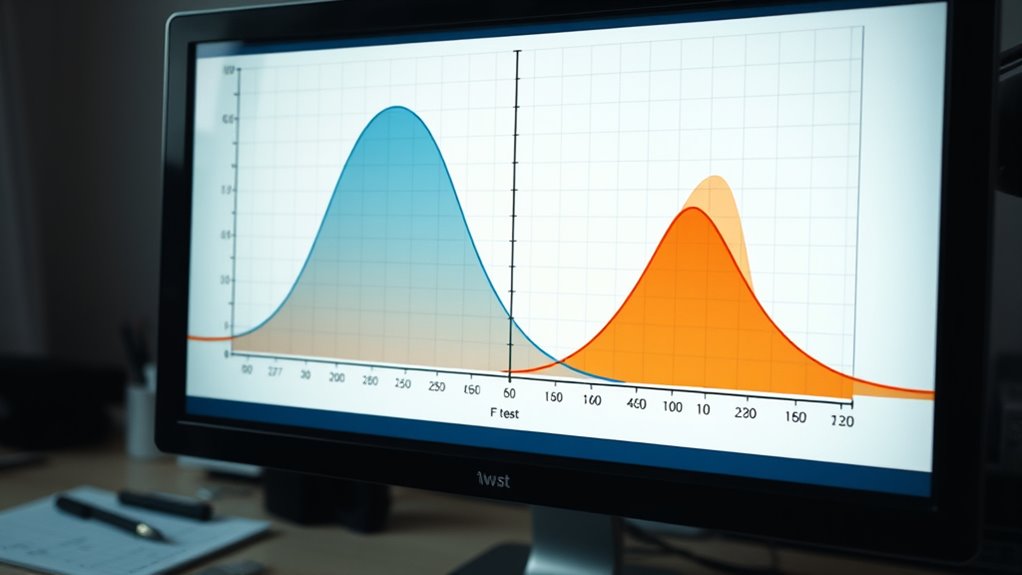
The F-test for equal variances is a statistical method used to determine whether two populations have similar variability. When you’re comparing two datasets, understanding if their variances are equal helps you decide which statistical tests to use next. The core idea is to assess the ratio of the variances from each sample. If the variances are similar, the ratio should be close to 1; if not, the ratio will notably deviate from 1, indicating unequal variances. Variance assumptions play a vital role in the F-test. You need to assume that both populations are normally distributed, as the test’s accuracy relies heavily on this. If the data deviates substantially from normality, the F-test’s results might be misleading. Hence, checking for normality before applying the test is essential. Also, keep in mind that the F-test is sensitive to outliers, which can inflate variances and skew your results. Making sure your data is clean and approximately normal helps maintain the validity of the test. Sample size considerations are equally important when performing an F-test. Ideally, both samples should be of sufficient size to produce reliable estimates of variance. Small sample sizes tend to produce less stable variance estimates, which can affect the test’s accuracy. When sample sizes are unequal, the test can still be used, but the interpretation becomes trickier. Larger, balanced samples improve the test’s robustness by reducing the impact of sampling variability. If your sample sizes are very different, you might consider alternative methods or transformations to guarantee more accurate results. Performing the F-test involves calculating the ratio of the sample variances, then comparing this ratio to a critical value from the F-distribution table, based on your chosen significance level and degrees of freedom. If your calculated ratio exceeds the critical value, you reject the null hypothesis, concluding that the variances are unequal. Conversely, if it’s within the range, you fail to reject the null, indicating similar variances. Remember that the choice of significance level affects the test’s sensitivity, so select it carefully based on your analysis context. Considering the impact of sample size on the test’s reliability can help improve your results.

Statistical Analysis with R For Dummies
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Frequently Asked Questions
How Does the F-Test Compare to Levene’s Test?
You compare the F-test and Levene’s test to assess variance homogeneity, but they serve different purposes. The F-test is sensitive to normality and works best with normally distributed data, while Levene’s test is more robust and handles non-normal distributions better. For test comparison, use Levene’s when data deviate from normality, and the F-test when variances are expected to be normally distributed, ensuring accurate variance homogeneity assessment.
Can the F-Test Be Used for Small Sample Sizes?
You should avoid using the F-test for small sample sizes because its reliability diminishes due to sample size limitations. Small samples can lead to misleading results, so consider alternative methods like Levene’s test or Bartlett’s test, which are more robust under these conditions. These alternatives handle small sample sizes better and provide more accurate assessments of variance equality, ensuring your analysis stays valid.
What Assumptions Must Be Met for Valid F-Test Results?
You need to guarantee your data meet specific assumptions for a valid F-test. First, your sample size should be sufficiently large for reliable results, especially with small samples. Second, data independence is vital; observations must not influence each other. Additionally, the populations should be normally distributed, although the test is somewhat robust to deviations in larger samples. Meeting these assumptions helps guarantee your F-test results are accurate and meaningful.
How Do Outliers Affect the F-Test Accuracy?
Outliers markedly impact the F-test accuracy by causing variance distortion, which can lead to misleading results. They increase the variability in your data, making it harder to accurately compare group variances. Outlier impact may inflate or deflate variances, skewing the F-statistic and risking incorrect conclusions about variance equality. To guarantee valid results, you should identify and address outliers before conducting the F-test.
Is the F-Test Applicable for Non-Normal Distributions?
The F-test isn’t very suitable for non-normal distributions because it’s sensitive to distribution assumptions. If your data isn’t normal, consider robust alternatives like Levene’s test or Bartlett’s test, which handle distribution sensitivity better. These tests provide more reliable results when normality isn’t met, ensuring your variance comparisons are accurate without being overly influenced by non-normal data, making your analysis more dependable across different data types.

Modes of Thinking for Qualitative Data Analysis
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Conclusion
Now, isn’t it intriguing how the F-test reveals whether your data groups share the same variance? By understanding this, you can confidently decide if your statistical assumptions hold true. It’s almost like uncovering a hidden pattern that guides your analysis. So, next time you’re faced with comparing variances, remember the F-test—it might just surprise you with what it uncovers about your data’s story. Who knew statistics could be so revealing?

Identify Diagnostics 12 Panel Urine Drug Test Cup Kit – 5 Pack
12 PANEL URINE DRUG TEST CUP KIT: Includes multiple screening panels in a single cup format designed for…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.

Klein Tools VDV501-851 Cable Tester Kit with Scout Pro 3 for Ethernet / Data, Coax / Video and Phone Cables, 5 Locator Remotes
VERSATILE CABLE TESTING: Cable tester tests voice (RJ11/12), data (RJ45), and video (coax F-connector) terminated cables, providing clear…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.