Clustering algorithms like K-Means and hierarchical methods help you find natural groups in data without labels. K-Means assigns points to clusters based on distance to initial centroids, then updates those centroids iteratively; running it multiple times improves results. Hierarchical clustering builds a tree-like structure called a dendrogram by merging or splitting data points using different linkage methods. Understanding how each works and choosing the right validations can reveal meaningful patterns—discover more details to sharpen your clustering skills.
Key Takeaways
- K-Means partitions data into N clusters by iteratively updating centroids based on Euclidean distance.
- Hierarchical clustering creates a tree (dendrogram) by merging or splitting data points using linkage methods.
- Choice of distance metric (Euclidean, Manhattan) influences cluster shape and quality in both algorithms.
- Validation techniques like silhouette scores assess cluster cohesion and separation for both methods.
- Multiple runs and proper validation ensure meaningful, stable clusters in K-Means and hierarchical approaches.
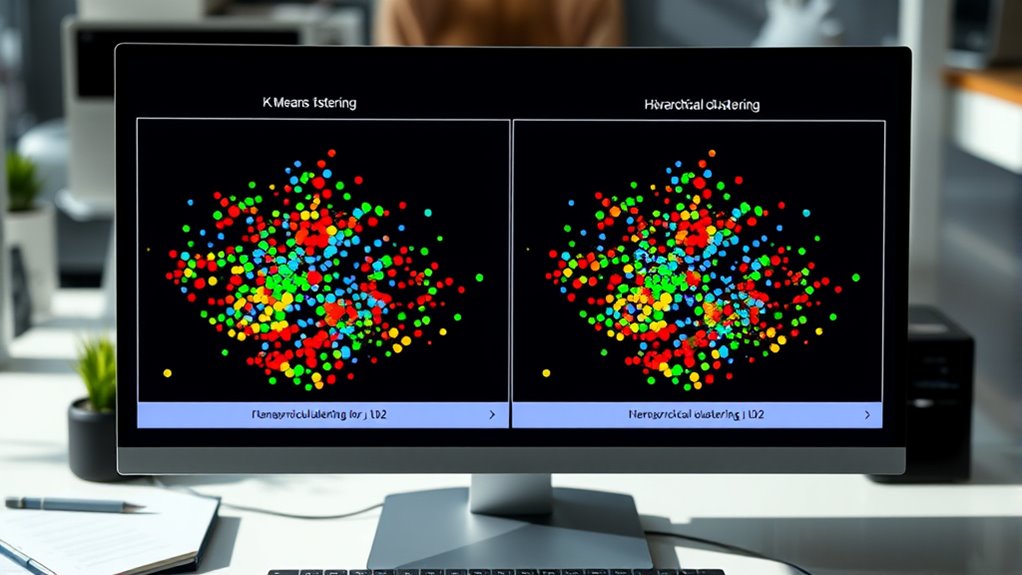
Clustering algorithms are powerful tools that help you uncover hidden patterns and group similar data points without prior labels. When you use these algorithms, choosing the right distance metrics becomes essential because they determine how you measure the similarity between data points. For example, Euclidean distance works well with continuous variables, while Manhattan distance might be better for high-dimensional data. Your choice of distance metric affects the shape and formation of clusters, so it’s worth experimenting with different options to see which yields the most meaningful groups. Once you form clusters, cluster validation becomes vital. Validation techniques, like silhouette scores or the Davies-Bouldin index, help you assess how well your clusters are separated and cohesive. They give you an objective way to evaluate whether your clustering results are meaningful or if adjustments are needed. Additionally, understanding the impact of different cluster validation metrics can guide you in selecting the most appropriate method for your specific dataset. If you’re working with K-Means, you’ll notice that it starts by randomly selecting centroids and then iteratively refines them. During each iteration, data points are assigned to the closest centroid based on your chosen distance metric, and then new centroids are recalculated based on the points assigned to each cluster. This process continues until the centroids stabilize or reach a set number of iterations. The effectiveness of K-Means heavily depends on the initial centroid placement, so running the algorithm multiple times with different seeds often helps find better solutions. Once the process ends, you should validate the resulting clusters to guarantee they make sense for your data. Using cluster validation metrics, you can compare different runs or parameter settings to select the best clustering configuration.
Hierarchical clustering takes a different approach. Instead of starting with random centers, it builds a tree-like structure called a dendrogram by either merging the closest pairs of data points or splitting larger clusters. The way data points are grouped depends on the linkage method you choose—single, complete, average, or Ward’s—each influencing how clusters are formed based on the distance metric. Hierarchical clustering provides a visual overview, making it easier to decide where to cut the dendrogram to get meaningful groups. Like with K-Means, validation remains important. You can cut the dendrogram at different levels and compute validation scores to find the best number of clusters. This helps guarantee that your clusters genuinely reflect the underlying data structure, rather than arbitrary splits.
K-Means clustering software
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Frequently Asked Questions
How Do I Choose the Right Number of Clusters for My Data?
You can choose the right number of clusters by using the Elbow Method, which looks for a point where adding more clusters doesn’t substantially improve the model, and the Silhouette Score, which measures how well data points fit within their clusters. Try both methods to find a balance—select the number of clusters where the Elbow Method shows a bend and the Silhouette Score peaks, indicating ideal grouping.
Can Clustering Algorithms Handle Categorical Data Effectively?
Think of clustering like sorting candies by color and flavor. Categorical data presents challenges because algorithms prefer numbers, so you need data encoding—like one-hot encoding—to translate categories into numerical form. While some algorithms handle categorical challenges well, others struggle. You should choose methods like hierarchical clustering or special algorithms designed for categorical data, ensuring your clusters truly reflect meaningful groupings without losing important categorical nuances.
What Are the Common Pitfalls When Applying K-Means?
When applying K-Means, you need to watch out for initialization sensitivity, which can lead to different results each time you run the algorithm. Poor initialization can also hinder cluster interpretability, making it harder to understand what the clusters represent. To avoid these pitfalls, consider using multiple runs with different initializations or methods like k-means++, which improve stability and clarity of your clusters.
How Do Hierarchical Clustering Methods Scale With Large Datasets?
You might find hierarchical clustering faces scalability challenges as dataset size grows, making it less practical for very large data. The method’s computational complexity increases quadratically with more data points, slowing down processing times and demanding more memory. While it offers detailed insights, you should be mindful that applying it to extensive datasets can be resource-intensive, requiring careful planning or alternative approaches to manage the workload effectively.
Are There Hybrid Approaches Combining K-Means and Hierarchical Clustering?
Yes, hybrid methods combining k-means and hierarchical clustering exist. You can use clustering integration to leverage the strengths of both algorithms—first applying k-means for fast initial grouping, then refining those clusters with hierarchical methods for better accuracy. This approach allows you to handle large datasets efficiently while achieving more meaningful clusters. Such hybrid approaches are particularly useful when you need scalable yet detailed clustering results.
hierarchical clustering analysis tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Conclusion
Now that you understand k-means and hierarchical clustering, you can confidently choose the right method for your data. Imagine you’re a marketer segmenting customers based on buying habits—clustering helps you tailor your campaigns effectively. Whether you’re analyzing customer data or organizing images, these algorithms simplify complex patterns. With this knowledge, you’ll access valuable insights and make smarter decisions, just like a data scientist transforming raw data into actionable strategies.
cluster validation metrics book
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
data clustering algorithms kit
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.