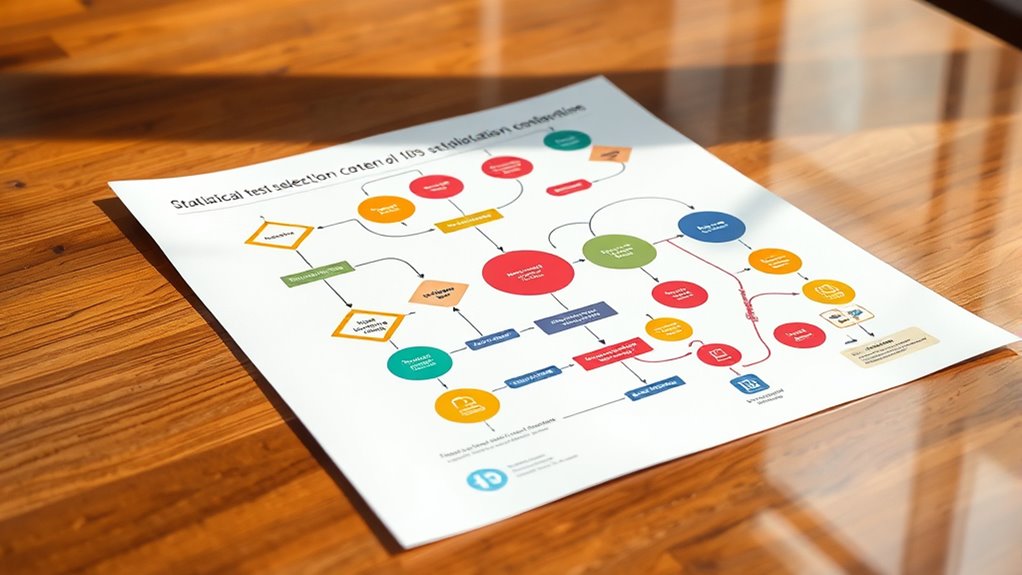

To choose the right statistical test, start by identifying your data type—nominal, ordinal, interval, or ratio—and considering your sample size. Check if your data meets assumptions like normality and equal variances for parametric tests; if not, opt for non-parametric options. Consider your research question and data distribution to select a test that balances robustness and sensitivity. Keep in mind each test’s limitations. Exploring these steps further helps make sure your analysis is accurate and trustworthy.
Key Takeaways
- Assess data type and measurement level (nominal, ordinal, interval, ratio) to determine suitable tests.
- Evaluate data distribution (normality) and variance equality to decide between parametric or non-parametric tests.
- Consider sample size; small samples may require specific tests like Fisher’s exact or non-parametric alternatives.
- Match test assumptions with data characteristics to ensure validity; avoid using tests with violated assumptions.
- Use a decision flowchart to systematically select the appropriate test based on data and analysis goals.

Selecting the appropriate statistical test is vital for accurately analyzing your data and drawing valid conclusions. When choosing a test, you need to consider various factors, including data assumptions and the limitations inherent to each test. Data assumptions refer to the conditions that your data must meet for a particular test to be valid. For example, many parametric tests assume that your data are normally distributed and that variances are equal across groups. If these assumptions aren’t met, the results can be misleading, leading you to incorrect inferences. That’s why it’s essential to evaluate your data’s characteristics before selecting a test; doing so helps avoid invalid results caused by violating test assumptions. Understanding test limitations is just as important. Every statistical test has its constraints—some are sensitive to outliers, small sample sizes, or non-normal distributions. For instance, a t-test works well with normally distributed data and larger samples but can give unreliable results if the data are skewed or if the sample size is tiny. Conversely, non-parametric tests like the Mann-Whitney U test don’t assume normality, but they might have less power to detect differences when parametric conditions are met. Recognizing these limitations helps you choose a test that balances robustness and sensitivity, ensuring your analysis remains valid under your specific data conditions. Additionally, understanding the types of data and their measurement levels can guide you toward the most suitable statistical methods. The decision process often begins with understanding your data’s level of measurement—whether it’s nominal, ordinal, interval, or ratio. For example, if you’re comparing two groups with continuous, normally distributed data, a t-test might be appropriate. But if your data violate normality assumptions or involve ordinal scales, you might need to opt for a non-parametric alternative like the Wilcoxon rank-sum test. When working with categorical data, chi-square tests are common, but they have limitations if sample sizes are small or if expected frequencies are low. In such cases, Fisher’s exact test provides a more reliable alternative, albeit with its own constraints. In essence, selecting the right statistical test requires a careful assessment of your data’s assumptions and limitations. By understanding these factors, you guarantee that your analysis accurately reflects your data’s story. Avoiding the pitfalls of invalid assumptions or test limitations leads to more credible, reliable conclusions. This process involves a thoughtful evaluation of your data’s distribution, measurement level, and sample size, guiding you toward a test that offers the best balance between validity and statistical power. In the end, making informed choices about your statistical tests helps you confidently interpret your results, paving the way for meaningful insights and robust research conclusions.
statistical test reference book
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Frequently Asked Questions
How Do I Handle Missing Data in My Analysis?
When handling missing data, you should consider data imputation to fill gaps accurately, ensuring your analysis remains robust. You might also perform sensitivity analysis to assess how different imputation methods affect your results, giving you confidence in your findings. Always document your approach and consider the extent and pattern of missingness to choose the most appropriate method, reducing bias and maintaining data integrity throughout your analysis.
Can I Use Multiple Tests for the Same Dataset?
Think of your dataset as a busy intersection with multiple roads. You can use multiple tests, but be cautious of data overlap, which can blur the results. Applying different tests helps explore various angles, yet it’s essential to avoid overloading your analysis. Carefully select tests suited to your data’s structure, ensuring each provides unique insights. This way, you balance thoroughness with clarity, making your findings more reliable and meaningful.
What Should I Do if Assumptions Are Violated?
If assumptions are violated, you should use robust methods that don’t rely heavily on those assumptions. First, perform assumption checks to identify issues. If violations are detected, consider alternative tests or data transformations. Robust methods, like non-parametric tests, can handle assumption violations better. Always validate your results with these methods to guarantee your conclusions remain reliable despite assumption breaches.
How to Interpret P-Values in Complex Analyses?
You interpret p-values in complex analyses by comparing them to your significance thresholds, usually 0.05. A p-value indicates the probability of observing your data if the null hypothesis is true. If it’s below the threshold, you consider the result statistically significant, suggesting evidence against the null. Remember, a small p-value doesn’t prove causation, but it helps you decide if the findings are unlikely due to chance.
When Is a Non-Parametric Test More Appropriate?
You should choose a non-parametric test when your data involves rank correlation or categorical data that doesn’t meet parametric assumptions like normality or equal variances. These tests, such as Spearman’s or Chi-square, are ideal because they don’t require the data to be normally distributed. Use them when your data is ordinal, skewed, or when sample sizes are small, ensuring valid and reliable results.
statistics flowchart poster
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Conclusion
Remember, selecting the right statistical test is vital for accurate results. By following this flowchart guide, you’ll avoid common pitfalls and make informed decisions. Keep in mind the adage, “A chain is only as strong as its weakest link”—so make certain your data and test choice align perfectly. With careful consideration, you’ll confidently interpret your data and draw meaningful conclusions, paving the way for credible and impactful research.
data analysis software for beginners
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
statistical test calculator
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.







